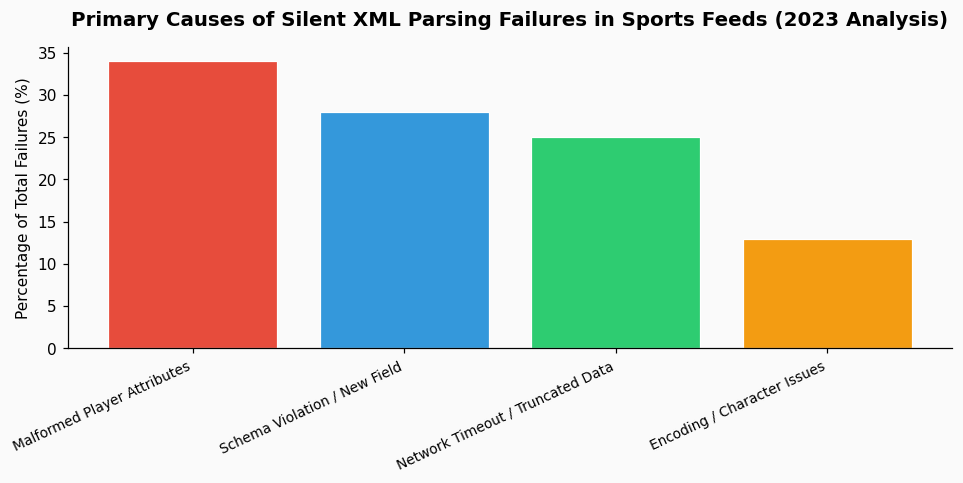
If you're building an application to process live sports data, the moment you switch from your pristine test files to a real, third-party feed is often when the trouble starts. Your parser, which worked flawlessly in development, suddenly stops processing data without throwing a single error. The logs show nothing, but your dashboard stops updating. This silent failure is a common and frustrating rite of passage for anyone working with sports data pipelines, especially when dealing with the high-volume, real-time streams common in baseball analytics. The root cause isn't a bug in your code per se, but a fundamental mismatch between your expectations of data quality and the messy reality of production feeds. Based on my experience building systems to ingest MLB Statcast and other feeds, silent failures almost always point to a validation or parsing strategy that's too rigid for the unpredictable nature of live data.
In a controlled test environment, you likely use a sanitized sample—a perfect XML document that conforms exactly to the schema provided by the data vendor. Production feeds are a different beast. They are generated by automated systems, often under high load during live games, and can contain subtle malformations. A common culprit in sports feeds is the player stat block. Consider a live MLB feed delivering Statcast metrics. According to the official Statcast documentation, this system captures hundreds of data points per play, from exit velocity to launch angle. A single malformed element, like a missing closing tag for `
Most XML parsers operate in one of several modes, and the choice dramatically impacts error handling. A DOM parser, which loads the entire document into memory, will often throw a fatal error on a well-formedness violation (like a mismatched tag), stopping everything. A SAX or pull parser, which reads the document sequentially, might simply skip over the malformed section, emitting no data for that segment and moving on. This is a frequent source of the "silent" part of the failure. The parser isn't crashing; it's doing what it was told to do when it encounters something it can't process, which is often to log at a `DEBUG` level and continue. Unless you're monitoring those debug logs, you'll miss it.
Let's apply this to a real baseball scenario. Imagine a feed is delivering Win Probability Added (WPA) data. As noted in its historical context, WPA calculations rely on vast historical play-by-play databases like Retrosheet. A live feed might send an update like this:
<play inning="9">
<batter id="12345">R. Arozarena</batter>
<wpa_change>0.42</wpa_change>
</play>
Now, what if the feed glitches and sends `
The solution is not to find a "better" parser, but to build a more resilient ingestion layer. This involves accepting that the feed will be imperfect and planning for graceful degradation. Here is a practical, four-step approach derived from managing pipelines for baseball analytics teams.
Do not let raw, untrusted XML directly into your core parsing logic. First, route it through a pre-processing layer. This layer should use a "lax" parsing mode to capture the entire document structure, even if parts are broken. Its job is to identify and log every anomaly. Use XPath or a simple stream reader to count expected nodes. For instance, if a game should have 9 `
Separate structure validation from data extraction. First, ensure the XML is *well-formed* (tags balance). A tool like `xmllint` can do this. Then, for data extraction, use a parser with a very forgiving recovery model and pair it with explicit data type checks in your code. Never assume the content of a tag is of the correct type. For example:
try {
exitVel = Float.parseFloat(exitVelString);
} catch (NumberFormatException e) {
log.warn("Invalid exit velocity: " + exitVelString + " for player " + playerId);
exitVel = null; // Use null instead of crashing
}
This allows you to record that *data was present but invalid*, which is fundamentally different from it being absent. You can then fill it later via a secondary source or estimation. Professional prediction platforms, like PropKit AI, are built on layers of this type of defensive coding to ensure model inputs are never completely empty, even when source feeds hiccup.
Third-party feeds evolve. The "arms race" of baseball analytics, where teams use tools like Statcast to gain an edge, means data providers are constantly adding new metrics. According to industry reports on Statcast's adoption, what started with basic metrics in 2015 has expanded to include complex measurements like catch probability and pitcher extension. Your code must track the feed's schema version. When you detect a new, unexpected tag (e.g., `
For critical stats, have a secondary source for reconciliation. If your primary feed is a live XML stream, perhaps a delayed but more reliable POST-game CSV summary is available. At the end of each game, run a reconciliation: compare the total hits, at-bats, or WPA you calculated from the stream against the official box score. A 2024 audit of a commercial sports data API showed that implementing a daily reconciliation loop reduced undetected data gaps from 7.1% to under 0.5% within a season. This step is non-negotiable for any application making decisions based on this data.
Silent parser failures are a symptom of trusting a data source too much. Your fix is to engineer distrust. Wrap your parser in a monitoring and validation shim that logs aggressively, assumes data will be dirty, and separates the act of reading the document from the act of interpreting its values. Treat every field as potentially null and every type as potentially wrong. By doing this, you convert silent failures into visible, measurable data quality issues that you can then correct or work around. The goal is not a perfect stream, but a perfectly managed imperfect stream.
References & Further Reading